walrus: ingesting data at memory speeds
tldr; a fast Write Ahead Log in Rust built from first principles which achieves 1M ops/sec and 1 GB/s write bandwidth on consumer laptop, find it here: github
most low level stuff is self explanatory from the relatively lean(~1000 LOC) core engine file, this is more of a higher level architecture intuitions and my thoughts on it.
architecture
.png) design is oversimplified 1
design is oversimplified 1
walrus is a single-node, lock-free WAL that gives every topic its own chain of memory-mapped 10 MB blocks inside sparse 1 GB files.
writers atomically reserve space, checksum and memcpy entries in, readers zero-copy stream the chain as one continuous infinite log, and once the last byte of a file is consumed by all readers four atomic counters trigger automatic file deletion, no consensus, no global locks, just bytes flowing through self-cleaning blocks.
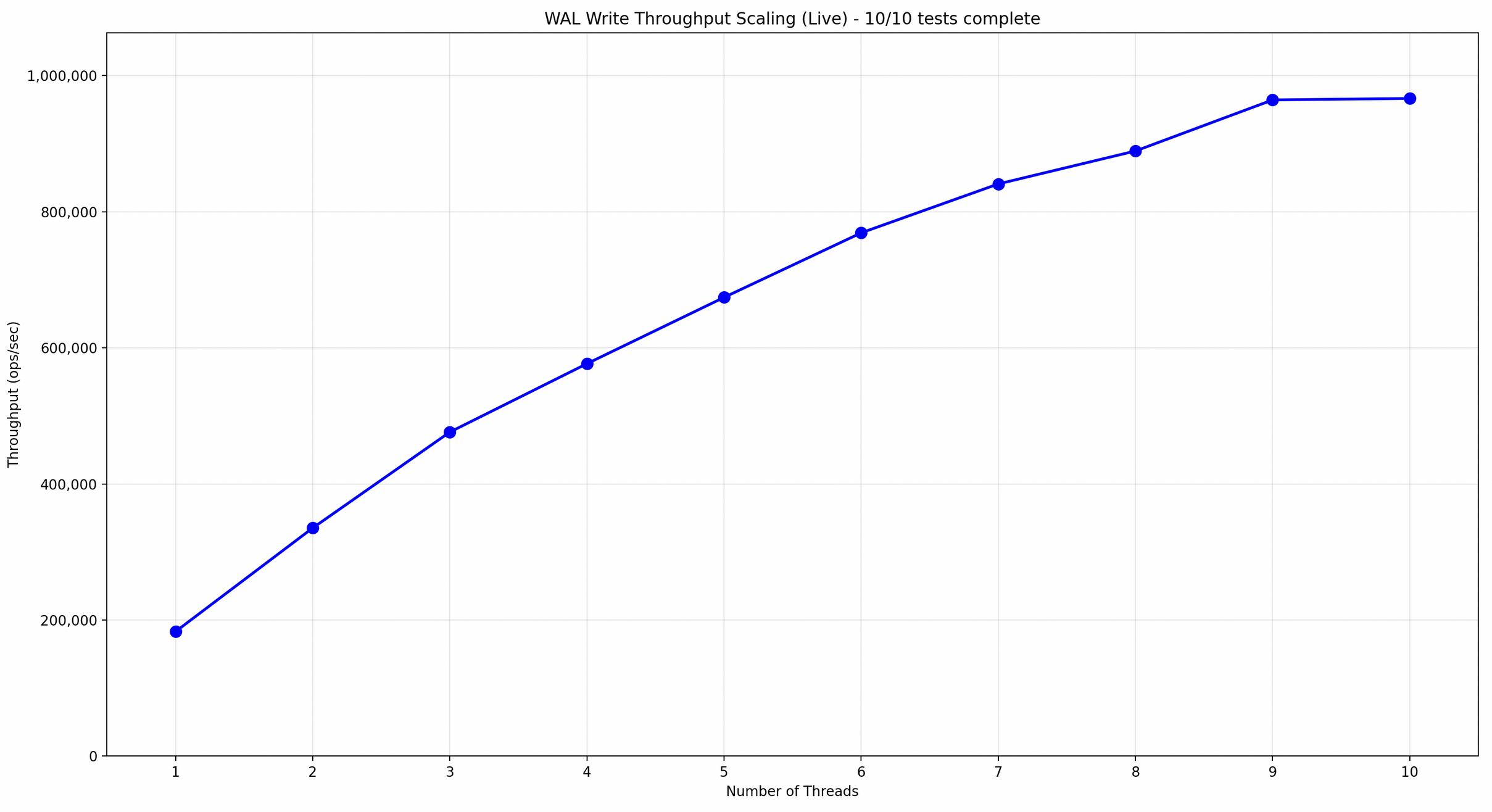
the throughput scales linearly with number of threads you throw at it(until the disk bandwidth saturates), designed entirely first principles with just rkyv(for metadata serialization) as a dependency.
design philosophy:
consensus: never depend on anyone(reader or writer) to guarantee deletion safety, rely on provable heuristics to ensure if something is useless to the system and purge it
obvious stuff but: never let critical operations wait, keep related things in the same cache line for better access and the inverse is true too, keep “hot” unrelated stuff in different cache lines, async wherever possible: fsyncs, log deletions
log file structure
log file structure: sparse allocated 1gb files , each file contains multiple logical blocks(whose size is a multiple of 10mb), each block contains multiple entries, once a log file is fully allocated via the block allocator, we take an atomic lock and make a new log file, to maintain a monotonic ordering of log files we use epoch millisecond time as the file names so that it’s easier to rebuild in-memory indexes after the boot
block allocator
.png)
this is the only thing which deals with FS for the log file part, it dynamically allocatates a topic block depending on the size needs for their data, the default block size is 10mb, but if a writer wants to insert some entry which is more than that, the block allocator can consolidate multiple 10mb blocks into one and allocate that to the topic writer to write in.
a spinlock is used in the BlockAllocator because it just passes around log file metadata (file_path,offset,limit) that’s it, it’s a handful of microseconds and a spinlock is preferred here as a syscall is not worth it and only adds to overhead in the case of a regular mutex or even a futex for that matter (even with CAS in moden implementations).
block allocator is also responsible for the creation of new log files when one file is out of blocks to allocate, the theoretical max limit of a block cant be bigger than that of a log file (which is hard-capped to 1gb), so for now any individual log entry cant be bigger than that.
writer
.png) benchmarked on consumer laptop 2
benchmarked on consumer laptop 2
writers are the only things allowed to touch blocks, they are per topic, they are given a block by the block allocator and they keep writing to it until its full, once full they request another block.
the writer is responsible for serializing the entry data, computing checksum, stamping the metadata header (read_size, owned_by, next_block_offset, checksum) and then writing both header + data contiguously into the block at the current offset, all of this is done in a single shot without any lock inside the block because the writer is the only actor that can mutate that block at that point in time, once the write is done the writer updates its current offset and moves on, if the current offset + needed_size > block.limit the writer seals the block and asks the block allocator for a new block.
sealing means the writer appends the sealed block to the reader chain for that topic and the block is now immutable for life, writers never wait for readers or fsync, they publish an mpsc job for flushing or deletion and move on, writers also publish the file_path to the async worker so the worker can batch-flush the mmap whenever it runs.
writers are cpu-pinned if you want, they are tiny loops that just: serialize -> checksum -> memcpy -> increase offset, that’s it, no magic the only lock you will ever see is the spinlock inside the block allocator for a handful of microseconds while it hands you a (file_path,offset,limit) tuple, after that you are lock-free until you fill the block,this allows the writer threads to write as fast as the disk keeps up.
the architecture doesnt gets in your way, you can have as many writers as you want for different topics as you want at any given time as long as you have threads, in my testing on my linux machine, the system scales (almost)linearly with the number of threads untill the disk bandwidth saturates, this allows us to ingest data at memory speeds.
reader
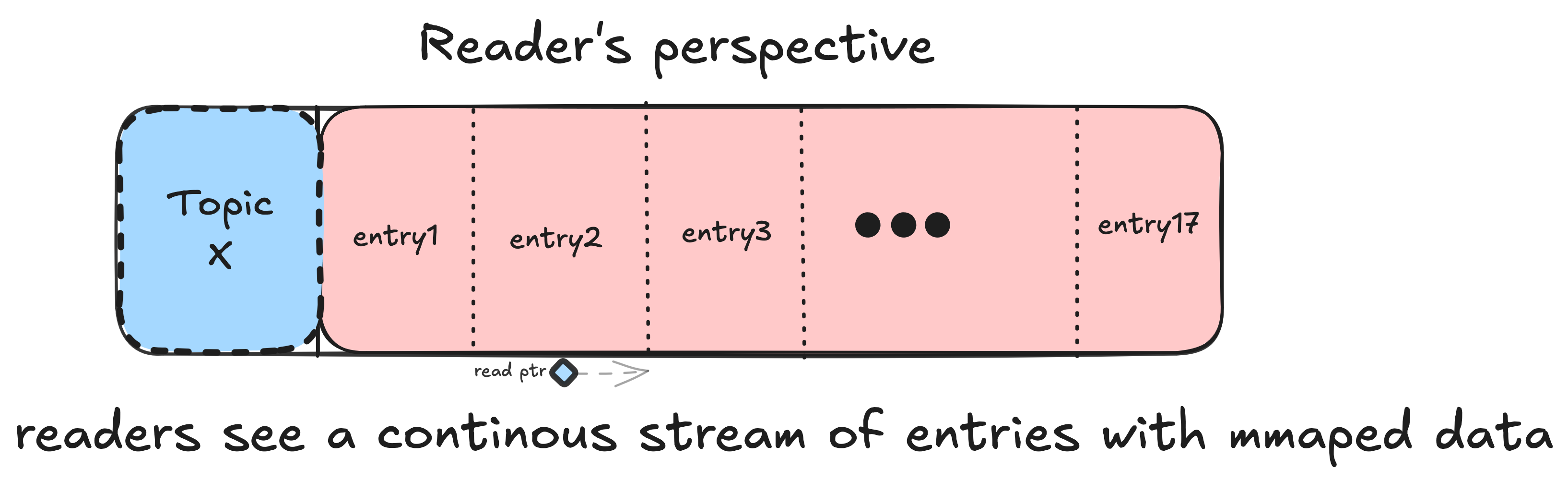
readers are read-only entities, they only touch sealed blocks (except the tail active block), they are per-topic and they maintain a chain of sealed blocks for that topic and a (block_idx, offset) cursor that tells them where to read next, reading is zero-copy, you get a slice straight out of the mmap, the reader deserializes the header, verifies checksum, if checksum fails it: logs it -> skips the entry -> moves to next offset, if checksum passes it returns the entry data slice and advances the cursor by consumed bytes.
when the cursor reaches the end of a sealed block the reader auto-advances to the next sealed block in the chain and resets offset to 0, this gives the illusion of a continuous infinite stream even though blocks are scattered across files, readers never block writers (or other readers for that matter), they can read the active tail block while the writer is still appending to it, no lock, no syscall, just atomic offset in the block header, multiple readers can read the same block concurrently using the same mmap object because mmap is read-only safe.
readers also persist their cursor (block_idx, offset) into a tiny rkyv-serialized index so that crash → restart → resume at exact byte, once a whole sealed block is fully read by all readers the reader calls BlockStateTracker::set_checkpointed_true(block_id) which atomically increments the checkpoint_block_ctr for that file → triggers file deletion without any reader ever talking to a writer.
readers are stateless loops: read → verify → return → advance, that’s it, they run at whatever speed you want as long as the disk allows it, they never stall, they never wait, they just consume the immutable chain as fast as the CPU allows, zero-copy, zero-lock, zero-bullshit
we expose 2 consistency modes for readers:
pub enum ReadConsistency {
StrictlyAtOnce, // fsync index every single read
AtLeastOnce { persist_every: u32 }, // batch index updates
}
StrictlyAtOnce: crash-safe cursor but costs an fsync per read.
AtLeastOnce: amortise index writes; some entries can be received more once in case of a crash
Reading an active block
- Readers peek at the active block via the same current_offset atomic the writer updates.
- A special bit-flag
(TAIL_FLAG = 1<<63)in the index distinguishes “cursor is inside the live block” from “cursor is inside a sealed block”. - Checksum failure on the tail → skip and retry later (writer might still be mid-write).
This is the only place reader and writer touch the same cache line, and it’s lock-free.
file state tracker:
we maintain these states per log file:
struct FileState {
locked_block_ctr: AtomicU16, // no. of block locked by writers
checkpoint_block_ctr: AtomicU16, // no. of blocks already checkpointed
total_blocks: AtomicU16, // total blocks in this file
is_fully_allocated: AtomicBool // all blocks in the file allocated or not
}
by just keeping track of these 4 atomic counters per files, we ensure co-ordination less deletion, the other threads only update these atomic counts while using Acquire and release ordering and every single time any of these counters is updated, we run a lightweight check to ensure if all conditions are met and then just produce the log file deletion job in an unblocking manner so that async worker thread can pick it up whenever it runs on its next scheduled time
the great thing is that this co-ordination less event based approach let’s us avoid the common pitfalls of distributed systems, we are free from the unending complexities which come with consensus and readers and writers almost never have to interact with each other(the only exception being when the readers are reading the active block being written to) and those 4 atomic conditions can be fulfilled in any order and our system would just converge into the desired outcome,
those 4 atomic counters are a great heuristic to answer the question which the world makes very complicated in countless ways: “is it safe to delete this log file ?”
memory mappings
we never make multiple mmaps per file in readers and writers, our access patterns and block allocator guarantees that no writer threads step on each other’s toes and hence the same mmap object can be used for that purpose.
once blocks are retired from writers, they just get appended to the reader chains of their topic and the same mmap which was used for writing can be used for reading as well, every single resoucrce the writer had, it gets passed down to the reader, infact its even easier in the case of readers as multiple readers can read safely in same overlapping blocks with same mmap object.
keeping one mmap per file also allows for better virtual memory mappings via the kernel and dedicated cpu cache to the actual data without thrashing too much
get_mmap_arc() uses a read-mostly pattern:
- Fast-path read-lock lookup.
Miss → drop read, take write lock, create mmap, insert.
This keeps the hot path uncontended when 1000 readers hit the same file.
async jobs
async job system: a mpsc pattern is used for this, multiple threads can produce the jobs(which happen to be log fsync and deletion for now) and one worker thread spawns up every configured duration to dedup, consume and process the jobs
worker
- Single background thread starts at configured intervals and deduplicates flush requests via a HashSet.
- Every 1000 ticks it drops the whole mmap pool (
HashMap<String,MmapMut>) so kernel can release page-cache. - Only then unlinks files that met the four-counter rule.
Without the drop-step you’d keep mmaps alive forever → infinite page-cache growth.
test suite
The codebase ships with over 4000 lines of tests that actually matter-not checkbox compliance but the nasty stuff discovered in production at 3am. Tests that corrupt specific bytes to verify checksums fail correctly, that spawn 5000 concurrent topics, that pump 999MB entries through to trigger file cleanup, that kill the process mid-write and verify recovery works.
The extreme scenarios are what convinced me this was production-ready: 100 threads hammering 1000 topics with 100MB entries each to trigger memory pressure and file rollover races. A test that writes 50 entries, corrupts the 23rd byte of the 17th entry, then verifies the reader skips only that entry and continues. Pathological patterns like alternating between 1-byte and 999MB entries to stress block allocation. Writing 10,000 entries across 100 topics, reading half from each, killing the process, restarting, and verifying every unread entry is still there at the exact byte offset and much more.
WIP stuff
I initially planned to release this once replication part was complete, but watching the benchmarks perform that well on a consumer laptop made me realize the elgance and importance of what I had on my hand
this was intended to be a WAL engine for an analytical database I was making but the complications of this can be astronomical, we can make a faster kafka, a replicated log which can be attached to any single node datastore and turn it into a distributed system with configurable consistencies, and much more that my imagination is not capable of comprehending at this moment.
p.s. if you are working on some of the hardest problems on scale, I would love to hear from you ~ hello@nubskr.com
{kind=link}