i built a high performance kv cache engine from scratch
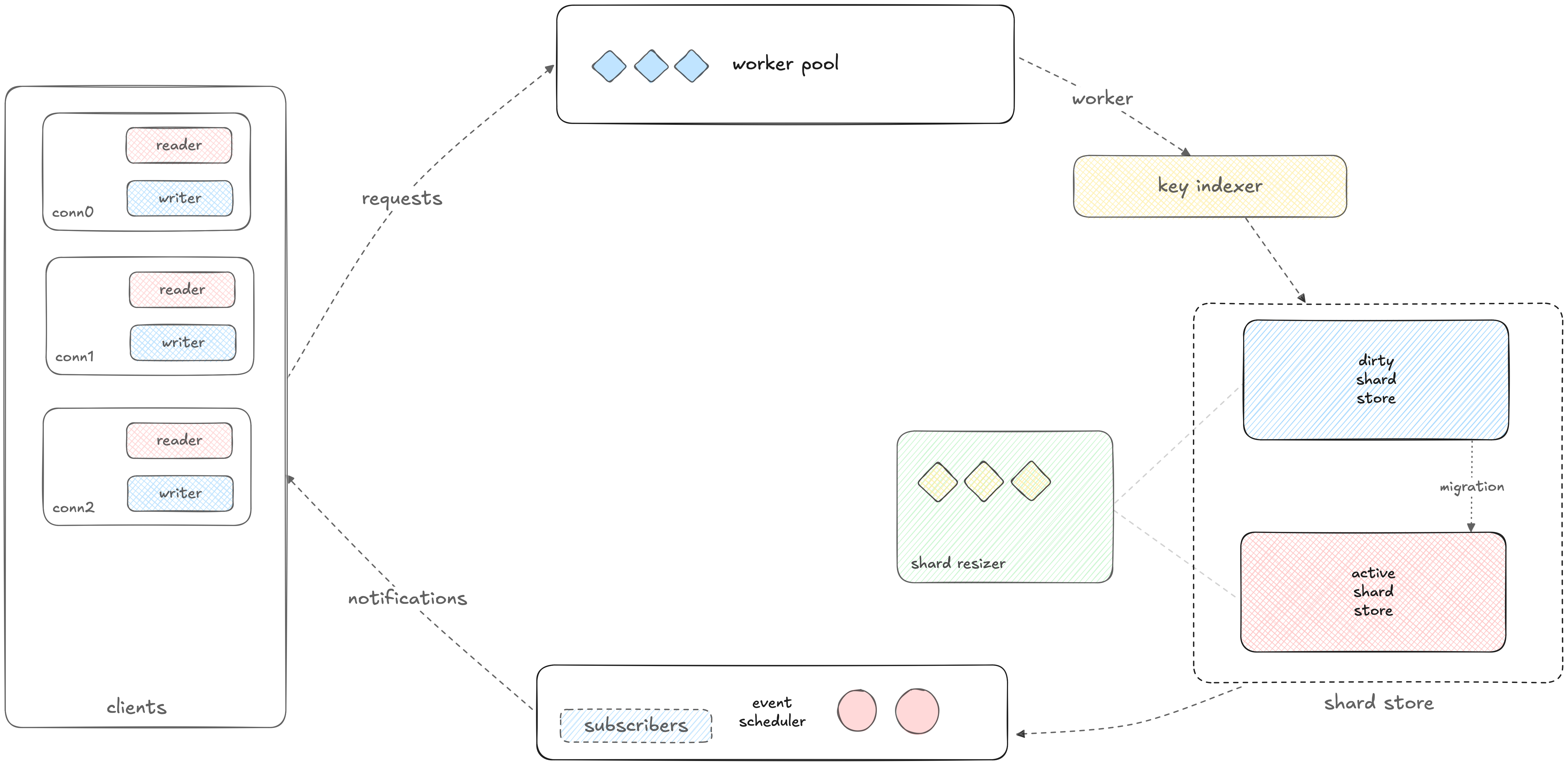
Core Architecture
Lock Contention Minimization
The system minimizes lock contention at multiple levels. It’s optimized for high-frequency write workloads since lock contention is kept to a minimum. Nearly all operations are lock-free.
Dynamic Scaling
The engine scales up and down dynamically on its own. When load per shard increases, the system spawns more shards in the new engine and migrates current keys to it. It can handle abuse better than anything else. Just run it and forget about it.
Dual-Engine Design
The system uses two engines. When one becomes too congested, write load shifts to a larger engine. Data from the old engine migrates to the new one in the background while the old engine continues serving reads. None of the current or incoming requests ever have to wait.
Each engine is essentially a large shard manager that handles multiple shards in a staircase format. Keys get assigned to shards through a hash function.
Features
TTL and Expiration
Keys support TTL functionality. When a key expires, subscribers to the expiration channel receive instant pub-sub notifications and the system stops serving that key. The expired keys get cleaned up by the garbage collector during the next upscale or downscale migration, at which point they’re completely purged from the system.
Pub-Sub
The pub-sub mechanism works really well. Notifications are nearly instantaneous in most cases.
Performance
All operations happen in memory. In recent benchmarking, the system achieved 900µs average write throughput and 500µs average read throughput with a million unique keys distributed across 50 clients hammering writes simultaneously.
Implementation
Built from the ground up using first principles. I had zero knowledge about how these systems work, just common sense and strong intuition. No dependencies whatsoever, pure Go implementation.
The system can function as either a high-performance cache layer or a NoSQL database by adjusting the upper bound working memory.
Benchmark Results
The system starts from bucket size 1 and scales up beautifully during benchmarks. The sharp dips in the graph show where the garbage collector kicks in and key migrations occur, temporarily affecting throughput. Engine resizing happens in the background, with pointers replaced when the new engine is ready to accept writes while the old one serves reads.
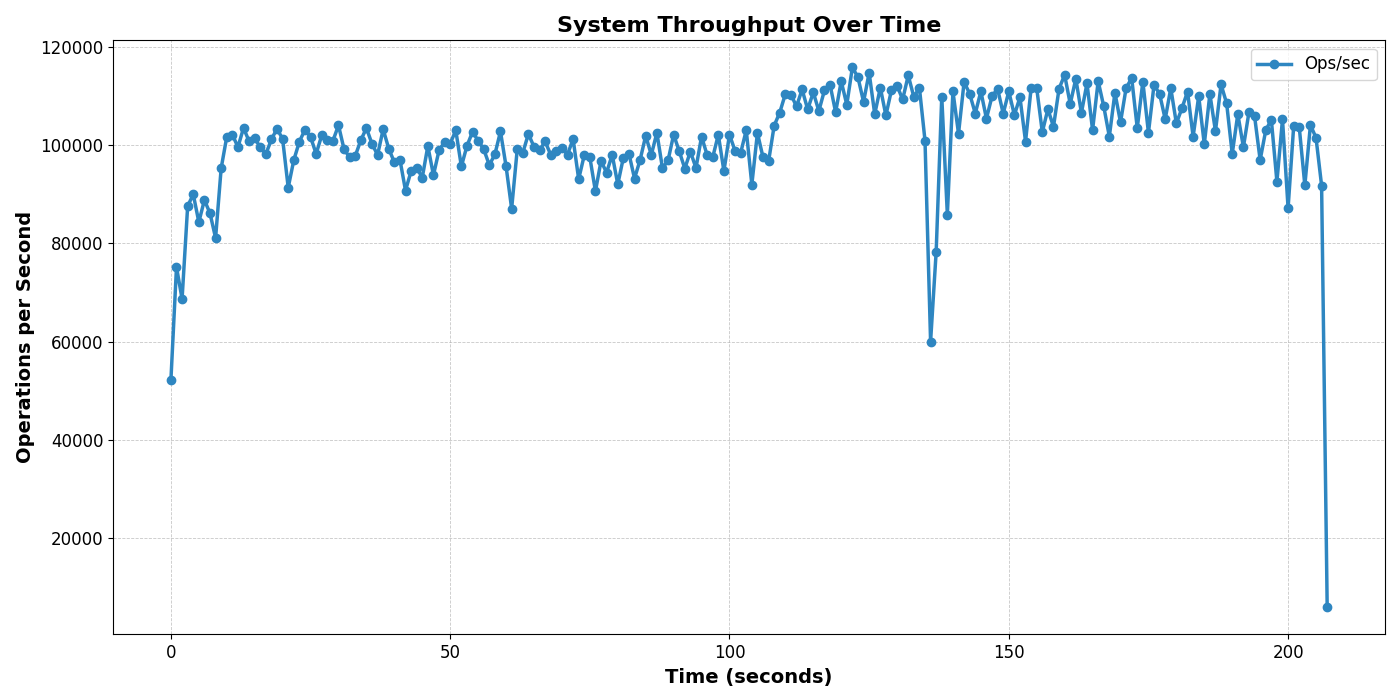
Test Environment: 8-core fanless M2 Air (all cores maxed under load)
- Concurrent clients: 100
- Peak throughput: 115,809 ops/sec
- Average throughput: 100,961.54 ops/sec
- Dataset size: 1,000,000 unique keys
- Total operations: 21,000,000 requests
- Total time tracked: 208 seconds