walrus v0.2.0: beating kafka at their own game
this post is in continuation to my v0.1.0 release post, 3 weeks ago I released the initial version of walrus and shared it with the community and receives quite a lot of invaluable feedback, I have attempted to include many of those changes in this release and more.
(if you havent read the initial post, please do so before reading this)
tldr. walrus v0.2.0 introduces new features like new FD based storage backend, new atomic batch write endpoints powered by io_uring, namespace isolation via key constructors and new fsync policies(FsyncSchedule::SyncEach, FsyncSchedule::NoFsync) among other improvements, I have also added competitive benchmarks with the likes of apache kafka, rocksdb WAL and much more.
find it here: github
this blog post is more of a higher level architecture intuitions and my thoughts on it.
Storage Backends
I received a lot of feedback regarding the brittleness of mmap after the initial release and realized that there would be scalability and stability challenges in the feature if I were to continue using it as the base for my storage engine.
so I added new file descriptor based storage backend, walrus uses that by default
we two new endpoints are added: batch_append_for_topic and batch_read_for_topic
On Linux with the FD backend enabled, Walrus batches multiple operations into a single syscall using io_uring. This is the key to sub millisecond batch operations.
batch_append_for_topicwrites up to 2000 entries atomically. On Linux, the fd backend drives io_uring submissions, otherwise writes fall back to sequential mmap I/O. this endpoint is atomic in nature, meaning when the operations succeeds/fails either nothing from the batch gets written or everything gets written.batch_read_for_topicreturns entries in commit order, respecting both a caller provided byte cap and the same 2000 entry ceiling and is capped to 10gb worth of entries to be read in a single batch for now
both of these endpoints respect the FsyncSchedule as the existing endpoints, infact FsyncSchedule:SyncEach is way faster this way as we can use O_SYNC with the file descriptors to avoid making another syscall to flush dirty pages to disk, this wasn’t possible earlier with mmap based storage backend.
the internal architecture of the batch write:
Rollback comes into play on any error during this replay. The code zeroes the metadata prefixes for every entry it planned (or just up to the failing entry in mmap mode), flushes that zeroed state to disk, restores the writer offset from BatchRevertInfo(which is just the rollback metadata we keep in memory), and releases every block id it had provisionally allocated.
Because the offset only advances after the entire plan flushes successfully, readers never see half finished entries.
the zeroed out header entries would be considered invalid and will be eventually overwritten whenever their blocks get reallocated, even if the system crashes after rollback,
the recovery mechanism after seeing the zeroed out headers will just skip the current block and move on to the next one, this ensures that we never read garbage.
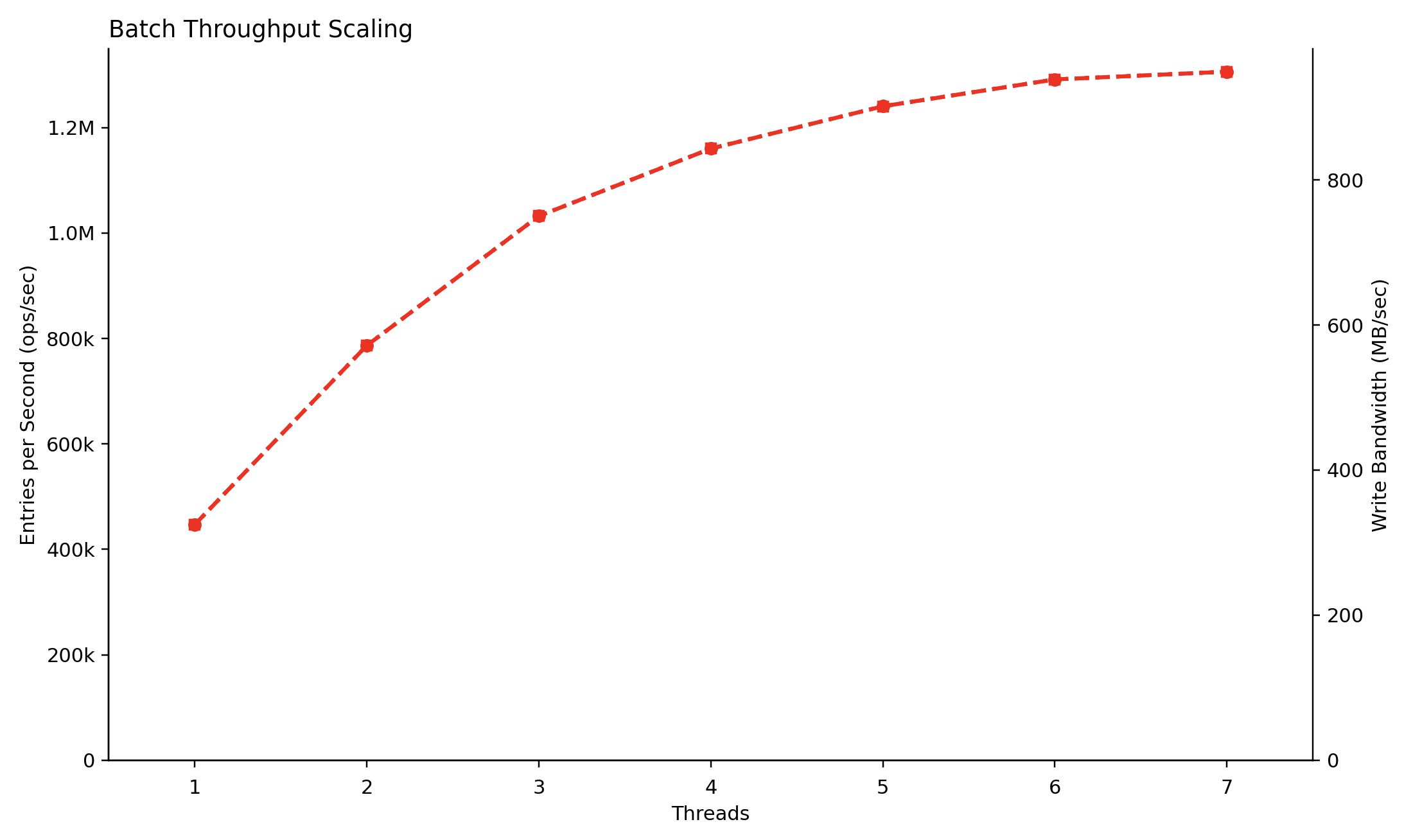
the batching endpoints help in achieving massive bandwidth with less number of threads, with just one thread I was getting ~400MB/s write bandwidth and 7 threads saturated my system’s bandwidth(which would have required way more threads if I were to use the regular append_for_topic() endpoint)
Batch reads complete in ~100-500 microseconds vs 2-10 milliseconds with traditional pread()
here is how the batch writes scales with number of threads with the io_uring magic
Fallback Behavior:
When io_uring is unavailable (non-Linux or mmap backend):
- Batch writes: Sequential
mmap.write()calls (still atomic via offset tracking) - Batch reads: Sequential
block.read()calls
Still correct, just slower (~5-10x overhead)
the future development will continue to prioritize linux and the mmap based storage engine will slowly be phased out
Not just a Write Ahead Log
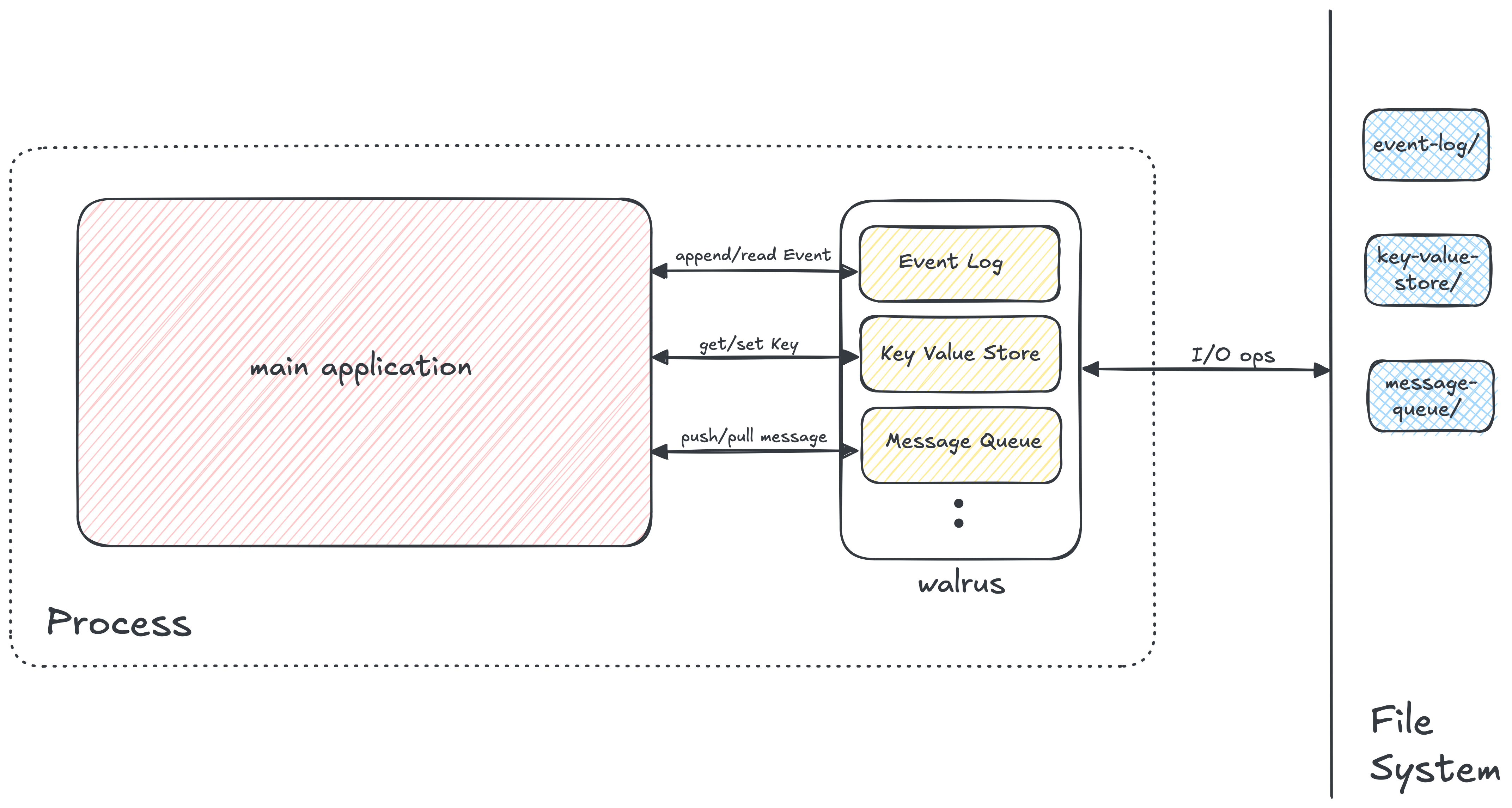
Walrus isn’t just a write ahead log anymore :), it’s a primitive for building complex components. Key based instance isolation means you can run multiple patterns in the same process, each with their own configuration and each optimized for different workloads.
use walrus::{Walrus, FsyncSchedule, ReadConsistency};
fn main() -> std::io::Result<()> {
// Event Log: Durable audit trail with strict ordering
let timeseries_event_log = Walrus::with_consistency_and_schedule_for_key(
"event-log",
ReadConsistency::StrictlyAtOnce,
FsyncSchedule::SyncEach
)?;
// Write Ahead Log: Maximum durability for database commits
let database_wal = Walrus::with_consistency_and_schedule_for_key(
"wal",
ReadConsistency::StrictlyAtOnce,
FsyncSchedule::SyncEach
)?;
// Message Queue: High throughput event streaming
let message_queue = Walrus::with_consistency_and_schedule_for_key(
"message-queue",
ReadConsistency::AtLeastOnce { persist_every: 1000 },
FsyncSchedule::Milliseconds(100)
)?;
// Key Value Store: Each key is a topic
let kv_store = Walrus::with_consistency_and_schedule_for_key(
"kv-store",
ReadConsistency::AtLeastOnce { persist_every: 100 },
FsyncSchedule::Milliseconds(50)
)?;
// Task Queue: Background job processing
let task_queue = Walrus::with_consistency_and_schedule_for_key(
"background-jobs",
ReadConsistency::AtLeastOnce { persist_every: 500 },
FsyncSchedule::Milliseconds(200)
)?;
Ok(())
}
Each Walrus instance gets its own isolated namespace on the filesystem. This isolation is complete WAL files, index files, and all metadata are stored in separate directories.
Filesystem Structure
wal_files/
├── event-log/ # Namespace for event log instance
│ ├── 1234567890123 # WAL file (timestamp)
│ ├── 1234567890456
│ └── read_offset_idx_index.db # Persisted read cursors
│
├── wal/
│ ├── 1234567891000
│ ├── 1234567891200
│ └── read_offset_idx_index.db
│
├── message-queue/
│ ├── 1234567892000
│ ├── 1234567892500
│ └── read_offset_idx_index.db
│
├── kv-store/
└── background-jobs/
Per instance isolation includes:
- WAL Files: Each instance creates its own timestamped WAL files (1GB each, 100 × 10MB blocks)
- Read Offset Index:
read_offset_idx_index.dbtracks cursors per topic within that namespace - Crash Recovery: Recovery scans only that instance’s directory, reducing blast radius
- Block Allocation: Block allocator operates independently per namespace
- Background Workers: Fsync workers only touch files in that namespace
Use Cases
- Timeseries Event Log: Immutable audit trails, compliance tracking. Every event persisted immediately, read exactly once.
- Database WAL: PostgreSQL style transaction logs. Maximum durability for commits, deterministic crash recovery.
- Message Queue: Kafka style streaming. Batch writes (up to 2000 entries), high throughput, at least once delivery.
- Key Value Store: Simple persistent cache. Each key is a topic, fast writes with 50ms fsync window.
- Task Queue: Async job processing. At least once delivery with retry safe workers (handlers should be idempotent).
Walrus handles I/O, block allocation, io_uring batching, crash recovery, and namespace isolation so you can focus on building your system.
benchmarks
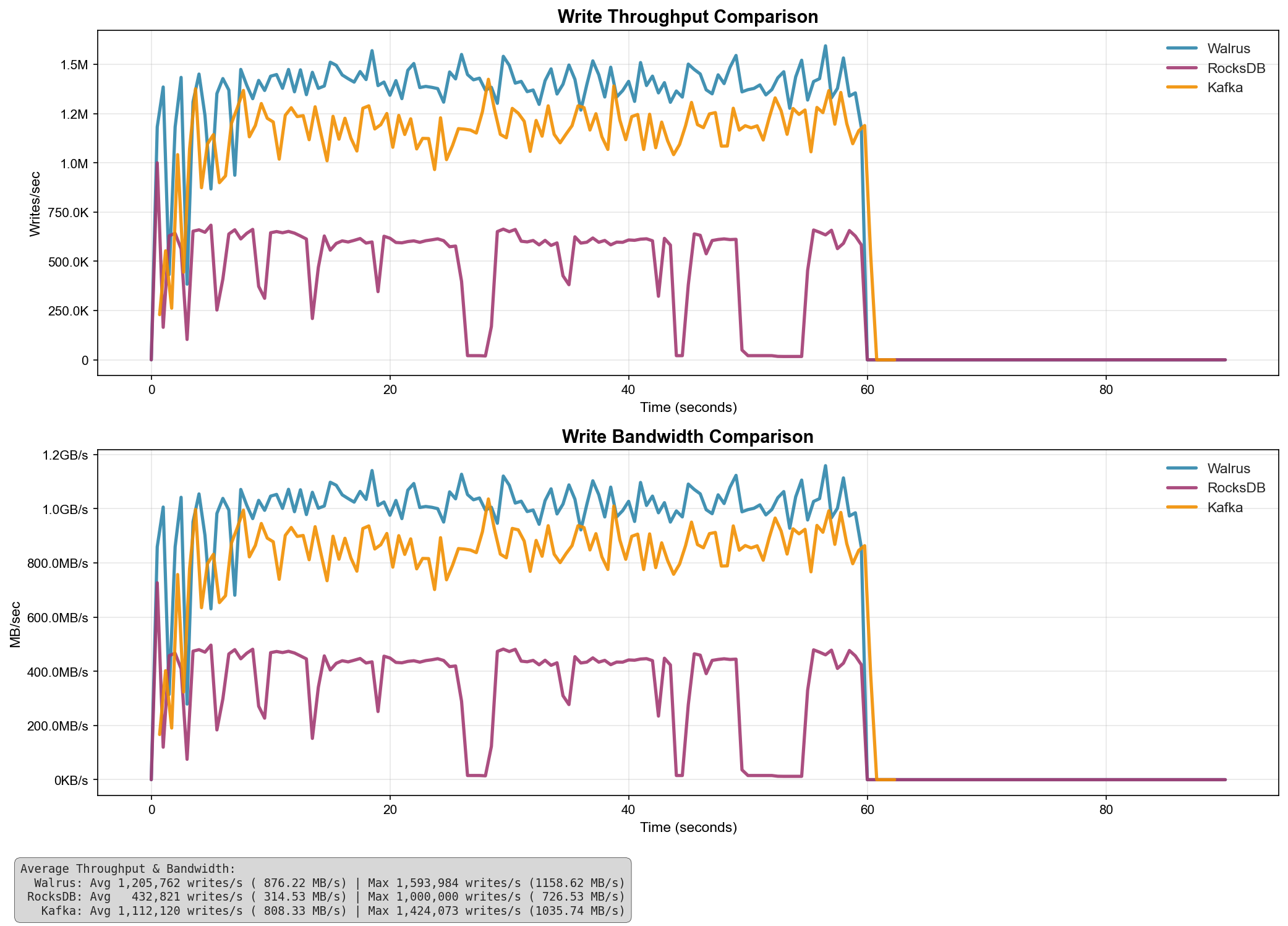
I benchmarked the latest version of walrus against single kafka broker(without replication, no networking overhead) and rocksdb’s WAL
 2
this performance is with the legacy
2
this performance is with the legacy append_for_topic() endpoint which uses pwrite() syscall for each write operation, no io_uring batching is used for these benchmarks
| System | Avg Throughput (writes/s) | Avg Bandwidth (MB/s) | Max Throughput (writes/s) | Max Bandwidth (MB/s) |
|---|---|---|---|---|
| Walrus | 1,205,762 | 876.22 | 1,593,984 | 1,158.62 |
| Kafka | 1,112,120 | 808.33 | 1,424,073 | 1,035.74 |
| RocksDB | 432,821 | 314.53 | 1,000,000 | 726.53 |
for synced writes:
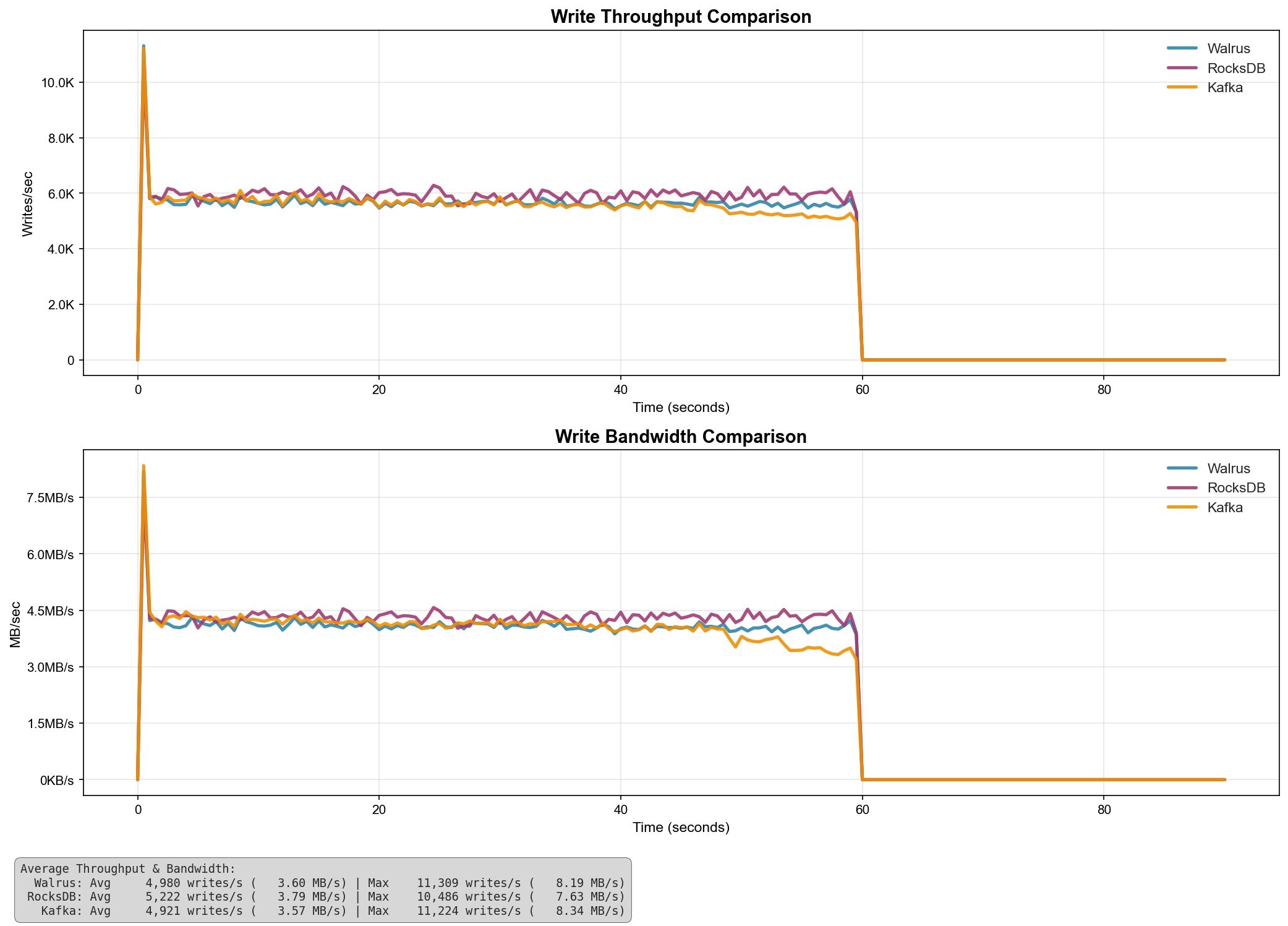
| System | Avg Throughput (writes/s) | Avg Bandwidth (MB/s) | Max Throughput (writes/s) | Max Bandwidth (MB/s) |
|---|---|---|---|---|
| RocksDB | 5,222 | 3.79 | 10,486 | 7.63 |
| Walrus | 4,980 | 3.60 | 11,389 | 8.19 |
| Kafka | 4,921 | 3.57 | 11,224 | 8.34 |
Afterthoughts
The core engine has grown to ~2.5k LOC, I’m currently working on a distributed engine to make walrus support replication and partitioning among other things, things are looking pretty good, distributed features should starting coming in within the new few releases.
p.s. I am looking for interesting things to do, if you are working on some of the hardest problems, I would love to hear from you ~ [email protected]
It’s been a long tiring day, I should really head to bed.
-
we currrently dont use the
IOSQE_IO_LINKflag in the submission queue for io_uring ops, further optimizations are planned in the upcoming releases which plan to include this, this would essentially enable us to ‘fail fast’ and would help with the overall latency of the batch endpoints ↩ -
all the tests were performed on linux, all the systems were configured similarily, the benchmark codes can be found here ↩